

Databases, types and Scaling Techniques.

I bring high energy and a strong commitment to guiding customers toward achieving their strategic business outcomes. I consistently operate with a big-picture mindset, aligning technology initiatives with long-term enterprise goals. Deeply passionate about innovation, I am a continuous learner who stays ahead of emerging technologies to deliver meaningful, measurable impact.
What is a Database?
A database is a repository of structured/unstructured information, or data, stored in a computer system. A database is usually controlled by a database management system (DBMS). Data in databases is commonly presented in rows and columns. This data can be managed by using SQL, which is a special language written to manipulate databases.
A database is information that is set up for easy access, management and updating. Computer databases typically store aggregations of data records or files that contain information, such as sales transactions, customer data, financials, and product information.
Databases are used for storing, maintaining, and accessing any sort of data(people, places and many more). In the modern age, data is generated in huge volume from all different sources - banking, social media, web, retail, health data and many more. Databases are used to store this invaluable data for business transactions or analytics purposes to make business decisions.That information is gathered in one centralized place so that it can be observed and analyzed. Databases can be thought of as an organized collection of information.
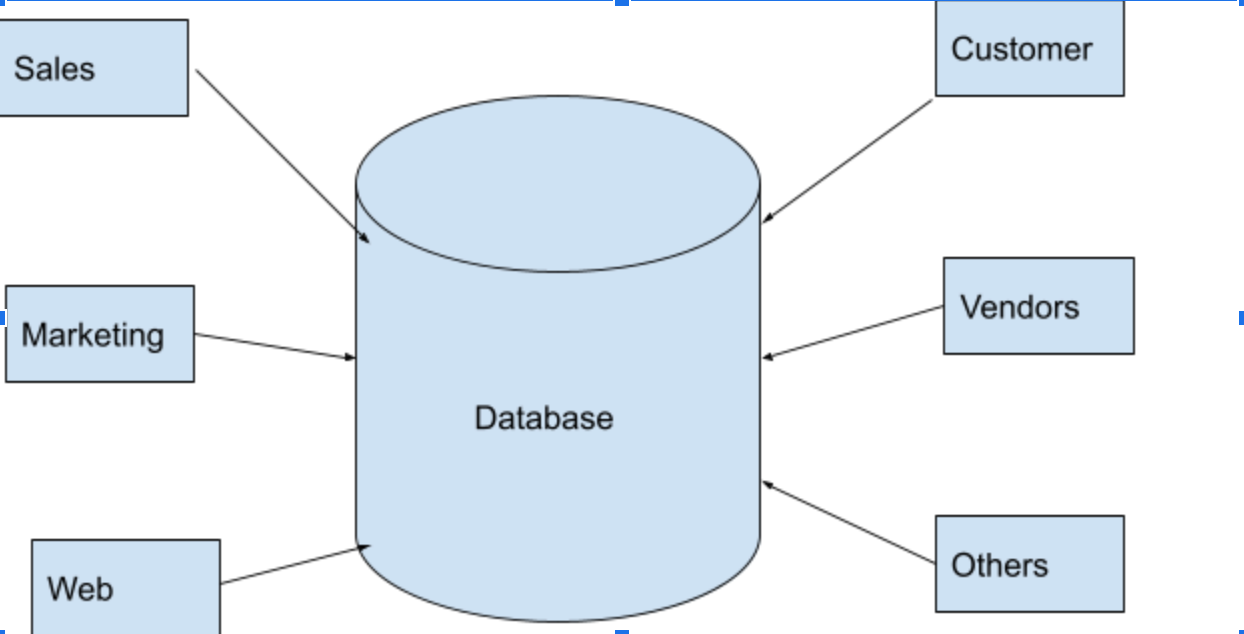
Scaling the Database
Databases are mission-critical applications for many enterprises. As a mission-critical application, the database must scale to meet an organization’s needs. There are several methods to increase the scalability of the database. Often it will take a combination of scaling methods to meet an organization’s needs.
Database scalability has three basic dimensions: amount of data, volume of requests and size of the requests. Requests come in many sizes: transactions generally affect small amounts of data but may approach thousands/millions per second; analytic queries are generally fewer but may access more data. A related concept is elasticity, the ability of a system to transparently add and subtract capacity to meet changing workloads.
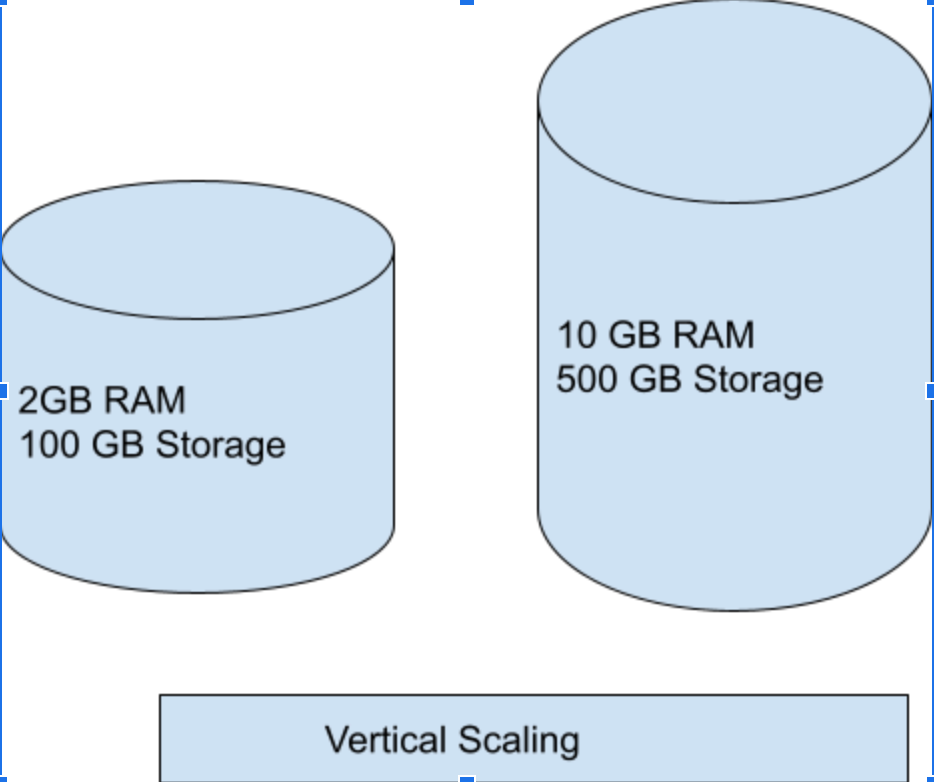
Every database must be scaled to address the huge amount of data being generated each day. In short, a database needs to be scalable so that it is always available. When the memory of the database is drained, or when it cannot handle multiple requests, it is not scalable. Scaling can be classified into Vertical (Scaling up) and Horizontal Scaling (Scaling out).
The first scaling method refers to scaling up versus scaling out. Scaling up refers to simply increasing the capacity of the server housing the database. At some point scaling up is not feasible, as a database can exceed the capacity of even the most powerful servers. Scaling out, by comparison, involves adding additional compute instances. Scaling out has two options: partitioning for NoSQL databases and read replicas for relational databases.
Vertical Scaling (Scaling up)
Vertical database scaling implies that the database system can fully exploit maximally configured systems, including typically multiprocessors with large memories and vast storage capacity. Such systems are relatively simple to administer but may offer reduced availability. However, any single computer has a maximum configuration. If workloads expand beyond that limit, the choices are either to migrate to a different, still larger system (with more storage and CPU) or to re-architect the system to achieve horizontal scalability.
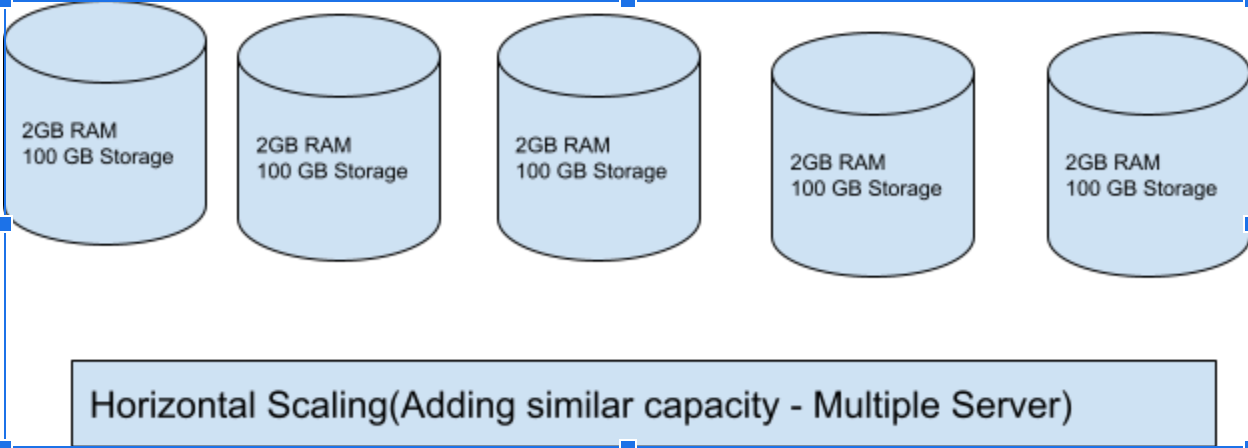
Horizontal Scaling (Scaling out)
Horizontal database scaling involves adding more servers to work on a single workload. Most horizontally scalable systems come with functionality compromises. If an application requires more functionality, migration to a vertically scaled system may be preferable.
Relational databases are scaled out by adding more servers, called read replicas. Read replicas are used to decrease the load in the main database by sending read requests to secondary read replica database servers. Use cases: when the application has a lot of read requests, query traffic slowing the main database down, analytical processing Scaling out for NoSQL Databases In a typical NoSQL database, the database is partitioned into multiple logical parts called Shards. Data is stored in these small partitions. The database system has the intelligence to route Read/Write traffic to the appropriate partition.
Database types:
Relational Databases
A relational database is a collection of data items with pre-defined relationships between them. These items are organized as a set of tables with columns and rows. Tables are used to hold information about the objects to be represented in the database.
Relational databases are also called SQL databases. SQL stands for Structured Query Language and it’s the language relational databases are written in. SQL is used to execute queries, retrieve data, and edit data by updating, deleting, or creating new records. Relational databases examples MySQL, Oracle, Microsoft SQL, PostgreSQL, AWS RDS.
Relational databases work best when organizations need high accuracy transactional queries such as retail or financial transactions. For example, An ATM withdrawal from one deposit account must commit the transaction immediately.
The diagram below shows how relational databases help show the relationship between different variables:
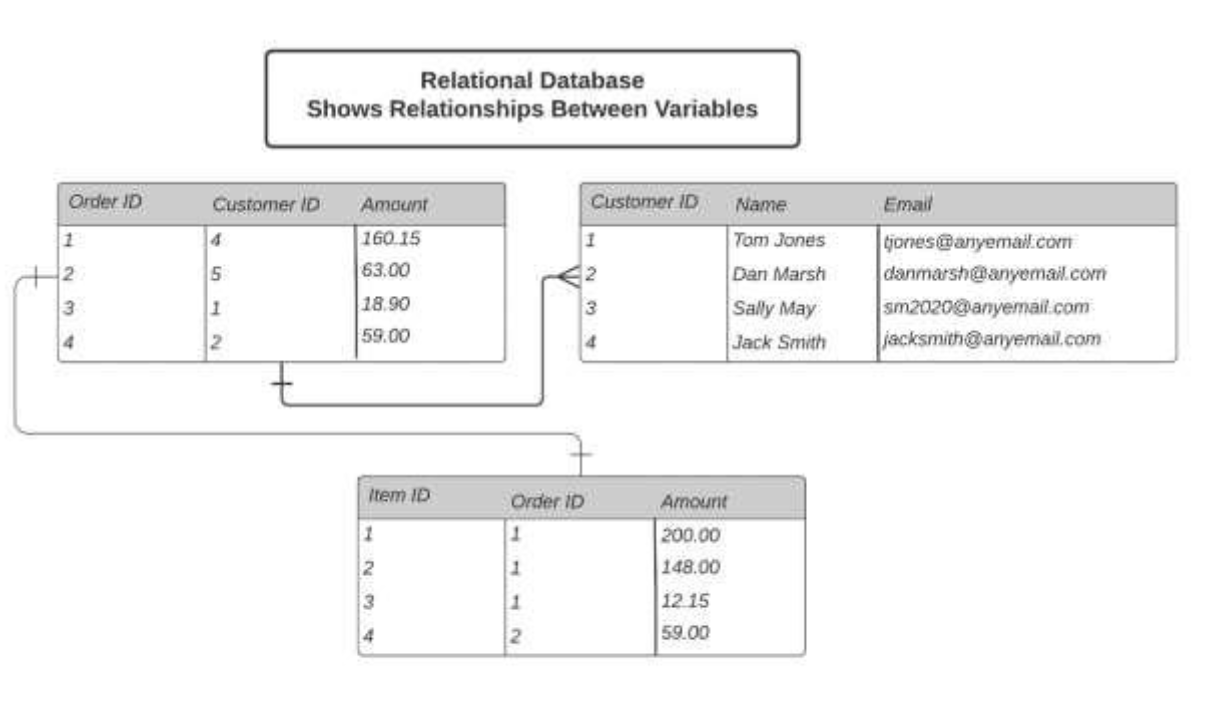
With relational databases, as soon as data is written, it will be immediately available for query. The instant consistency is based upon relational databases following the ACID model. More information on the ACID model can be seen below:
- Atomic – Transactions are all or nothing.
- Consistent – Data is consistent immediately after writing to the database.
- Isolated – Transactions do not affect each other.
- Durable – Data in the database will not be lost.
Note : Generally you can scale up relational databases.
AWS Relational Databases: AWS RDS, AWS Aurora, etc
NoSQL Databases
A NoSQL database stands for “not only SQL”. NoSQL databases facilitate enhanced flexibility and scalability by allowing a more flexible database schema. Non-relational databases use a storage model that is optimized for the specific requirements of the type of data being stored. For example, data may be stored as simple key/value pairs, as JSON documents, non-relational databases are also known as NoSQL databases which stands for “Not Only SQL.” Where relational databases only use SQL, non-relational databases can use other types of query language.
NoSQL databases are optimal under the following circumstances: When you need to store large amounts of unstructured data. When the database schema may change. When you need flexibility. When an organization needs rapid deployment of the database and availability is more crucial.
Note : Generally you can scale out non relational/NoSQL databases.
The diagram below shows how NoSQL databases work with key value pairs.
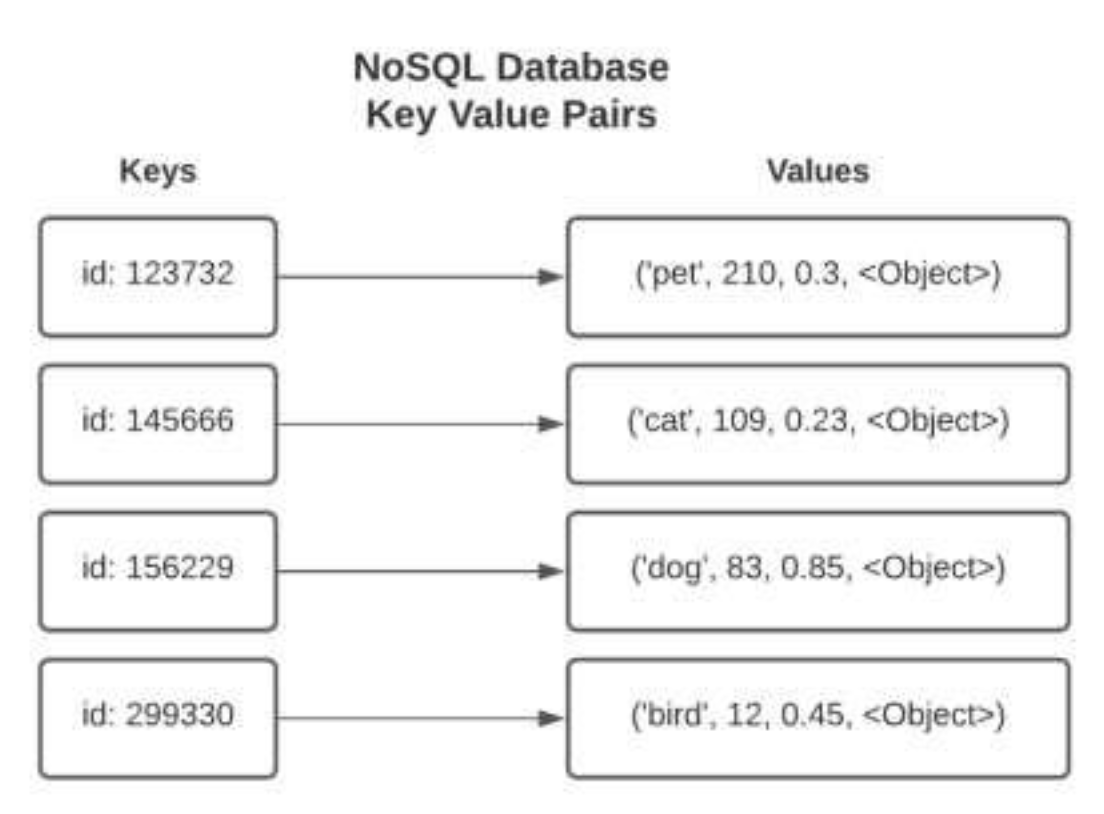
Non-relational databases examples Apache Cassandra Google Cloud BigTable Apache HBase MongoDB Amazon DynamoDB
AWS NoSQL Databases:
- Amazon DynamoDB.
- Amazon DocumentDB
- Amazon Keyspaces (for Apache Cassandra)
- Amazon Neptune.
- Amazon Timestream.
- Amazon Quantum Ledger Database (QLDB)
Conclusion:
In this blog we learned about databases, types and scaling techniques.




